The following is an R coding excerise on loading, viewing, processing, and visualizing data in R. We complete all analysis on the gapminder dataset.
All code chunks are echoed for ease of viewing.
The following chunk loads all libraries which will be used during this exercise.
## install packages and load required libraries# install.packages("dslabs") #lines to install required packages are commentedlibrary(dslabs) #load dslabs library# install.packages("tidyverse") #install and load tidyverselibrary(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
# install.packages("here")library(here)
here() starts at /Users/chirst/Desktop/Git/corahirst-MADA-portfolio
# install.packages("gtsummary")library(gtsummary)
#StandWithUkraine
# install.packages("flextable")library(flextable)
Attaching package: 'flextable'
The following objects are masked from 'package:gtsummary':
as_flextable, continuous_summary
The following object is masked from 'package:purrr':
compose
Loading and checking the data
Below, we familiarize ourselves with the most recent dataset from the package gapminder.
# pull information on the gapminder packagehelp(gapminder) #open help file for gapminder dataset# structure of the gapminder dataset?str(gapminder) # what is the class of the gapminder dataset? how many variables? class of each variable?
'data.frame': 10545 obs. of 9 variables:
$ country : Factor w/ 185 levels "Albania","Algeria",..: 1 2 3 4 5 6 7 8 9 10 ...
$ year : int 1960 1960 1960 1960 1960 1960 1960 1960 1960 1960 ...
$ infant_mortality: num 115.4 148.2 208 NA 59.9 ...
$ life_expectancy : num 62.9 47.5 36 63 65.4 ...
$ fertility : num 6.19 7.65 7.32 4.43 3.11 4.55 4.82 3.45 2.7 5.57 ...
$ population : num 1636054 11124892 5270844 54681 20619075 ...
$ gdp : num NA 1.38e+10 NA NA 1.08e+11 ...
$ continent : Factor w/ 5 levels "Africa","Americas",..: 4 1 1 2 2 3 2 5 4 3 ...
$ region : Factor w/ 22 levels "Australia and New Zealand",..: 19 11 10 2 15 21 2 1 22 21 ...
# summarize the gapminder datasummary(gapminder) #gives summary statistics for each numeric variable and count information for each categorical variable
country year infant_mortality life_expectancy
Albania : 57 Min. :1960 Min. : 1.50 Min. :13.20
Algeria : 57 1st Qu.:1974 1st Qu.: 16.00 1st Qu.:57.50
Angola : 57 Median :1988 Median : 41.50 Median :67.54
Antigua and Barbuda: 57 Mean :1988 Mean : 55.31 Mean :64.81
Argentina : 57 3rd Qu.:2002 3rd Qu.: 85.10 3rd Qu.:73.00
Armenia : 57 Max. :2016 Max. :276.90 Max. :83.90
(Other) :10203 NA's :1453
fertility population gdp continent
Min. :0.840 Min. :3.124e+04 Min. :4.040e+07 Africa :2907
1st Qu.:2.200 1st Qu.:1.333e+06 1st Qu.:1.846e+09 Americas:2052
Median :3.750 Median :5.009e+06 Median :7.794e+09 Asia :2679
Mean :4.084 Mean :2.701e+07 Mean :1.480e+11 Europe :2223
3rd Qu.:6.000 3rd Qu.:1.523e+07 3rd Qu.:5.540e+10 Oceania : 684
Max. :9.220 Max. :1.376e+09 Max. :1.174e+13
NA's :187 NA's :185 NA's :2972
region
Western Asia :1026
Eastern Africa : 912
Western Africa : 912
Caribbean : 741
South America : 684
Southern Europe: 684
(Other) :5586
# although the str() function gives the dataset class, we can check with the function class()class(gapminder) #gives the class of the r object gapminder
[1] "data.frame"
The gapminder dataset is an object of class “data.frame”. Each row of the dataframe contains health and income outcomes for some year for some country. The dataframe contains 9 columns, for country name, region, and continent; the year of the observation; and 5 different demographic, health, and income outcomes for each observation. These outcomes consist of infant_mortality, life_expectancy, fertility, population, and gdp.
There are 10545 observations in total, gathered from 184 countries between the years of 1960 and 2016.
Processing the data
Here, we are going to select and process data on african countries from the gapminder dataset.m
# subset rows from dataset containing factor level 'Africa' from column "continent"africadata = gapminder %>%filter(continent =="Africa") #dplyr's filter() function accomplishes this# create life expectancy subsets of africadata containing 1) infant mortality and life expectancy and 2) population and life expectancy africa.IMvsLE = africadata %>%select("infant_mortality", "life_expectancy") #dplyrs select() function subsets columnsafrica.PvsLE = africadata %>%select("population", "life_expectancy") # structure of the life expectancy subsetsstr(africa.IMvsLE) #2907 observations, 2 columns (variables)
'data.frame': 2907 obs. of 2 variables:
$ infant_mortality: num 148 208 187 116 161 ...
$ life_expectancy : num 47.5 36 38.3 50.3 35.2 ...
'data.frame': 2907 obs. of 2 variables:
$ population : num 11124892 5270844 2431620 524029 4829291 ...
$ life_expectancy: num 47.5 36 38.3 50.3 35.2 ...
# summary of variables in life expectancy subsetssummary(africa.IMvsLE) #summary stats of both columns containing numerical values
infant_mortality life_expectancy
Min. : 11.40 Min. :13.20
1st Qu.: 62.20 1st Qu.:48.23
Median : 93.40 Median :53.98
Mean : 95.12 Mean :54.38
3rd Qu.:124.70 3rd Qu.:60.10
Max. :237.40 Max. :77.60
NA's :226
summary(africa.PvsLE) #summary stats of both columns contain numerical values
population life_expectancy
Min. : 41538 Min. :13.20
1st Qu.: 1605232 1st Qu.:48.23
Median : 5570982 Median :53.98
Mean : 12235961 Mean :54.38
3rd Qu.: 13888152 3rd Qu.:60.10
Max. :182201962 Max. :77.60
NA's :51
The code chunk above isolates the 2907 observations from african countries only within the gapminder dataset and stores this subset in the “data.frame” object, africandata. Two subsets of the africandata data frame are generated. The first, africa.IMvsLE, contains two columns showing the values of variables infant_mortality and life_expectancy for each observation. The second, africa.PvsLE, contains two columns showing the values of variables population and life_expectancy for each observation.
Plotting
The following code chunk generates two plots, visualizing the association of either infant_mortality or population with life_expectancy across Africa between 1960-2016.
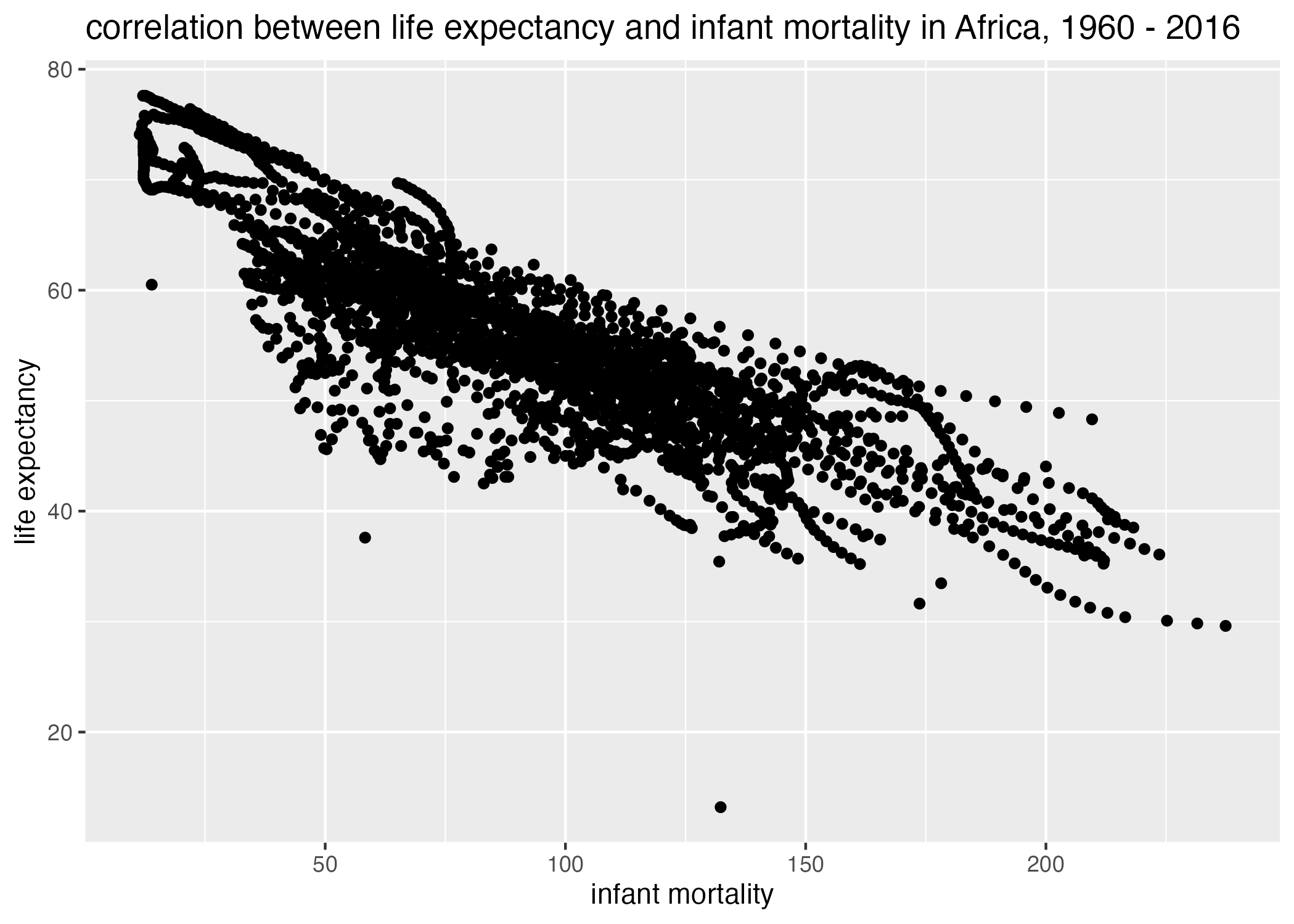
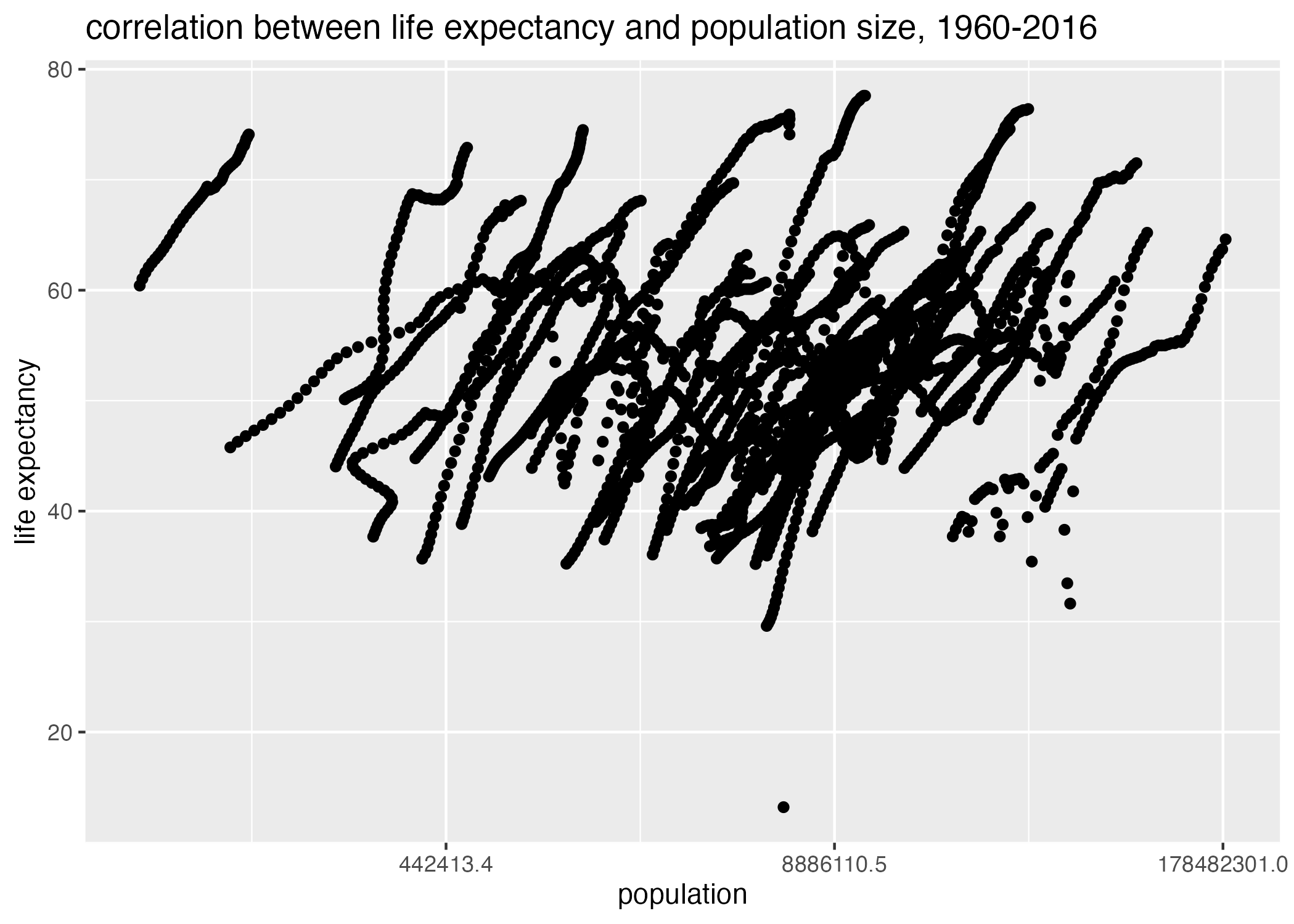
#life_expectancy vs infant_mortality plot1 =ggplot() +geom_point(data = africa.IMvsLE, aes(x = infant_mortality, y = life_expectancy)) +labs(x ="infant mortality", y ="life expectancy", title ="correlation between life expectancy and infant mortality in Africa, 1960 - 2016")plot2 =ggplot() +geom_point(data = africa.PvsLE, aes(x = population, y = life_expectancy)) +scale_x_continuous(trans ="log") +labs(x ="population", y ="life expectancy", title ="correlation between life expectancy and population size, 1960-2016")figure_file =here("coding-exercise","results", "figures","life_exp_inf_mort_all.png")ggsave(filename = figure_file, plot=plot1)
Figure 1: life expectancy by infant mortality, Africa, 1960-2016.
Figure 2: life expectancy by population size, Africa, 1960-2016.
Obviously, there appear to be clusters of data associated with the variables infant_mortality and population. These clusters may be the result of fixed effects from another associated variable, such as year.
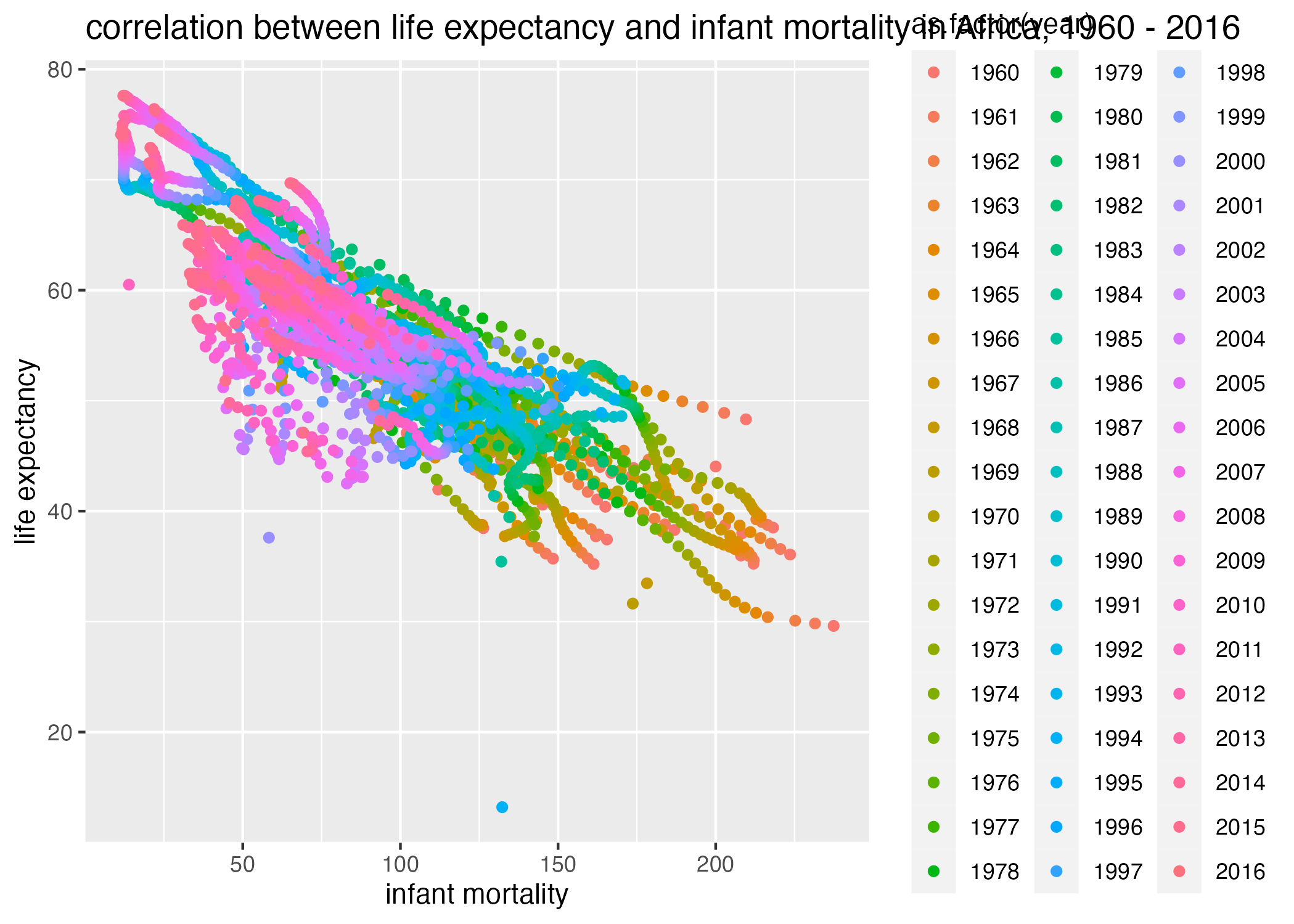
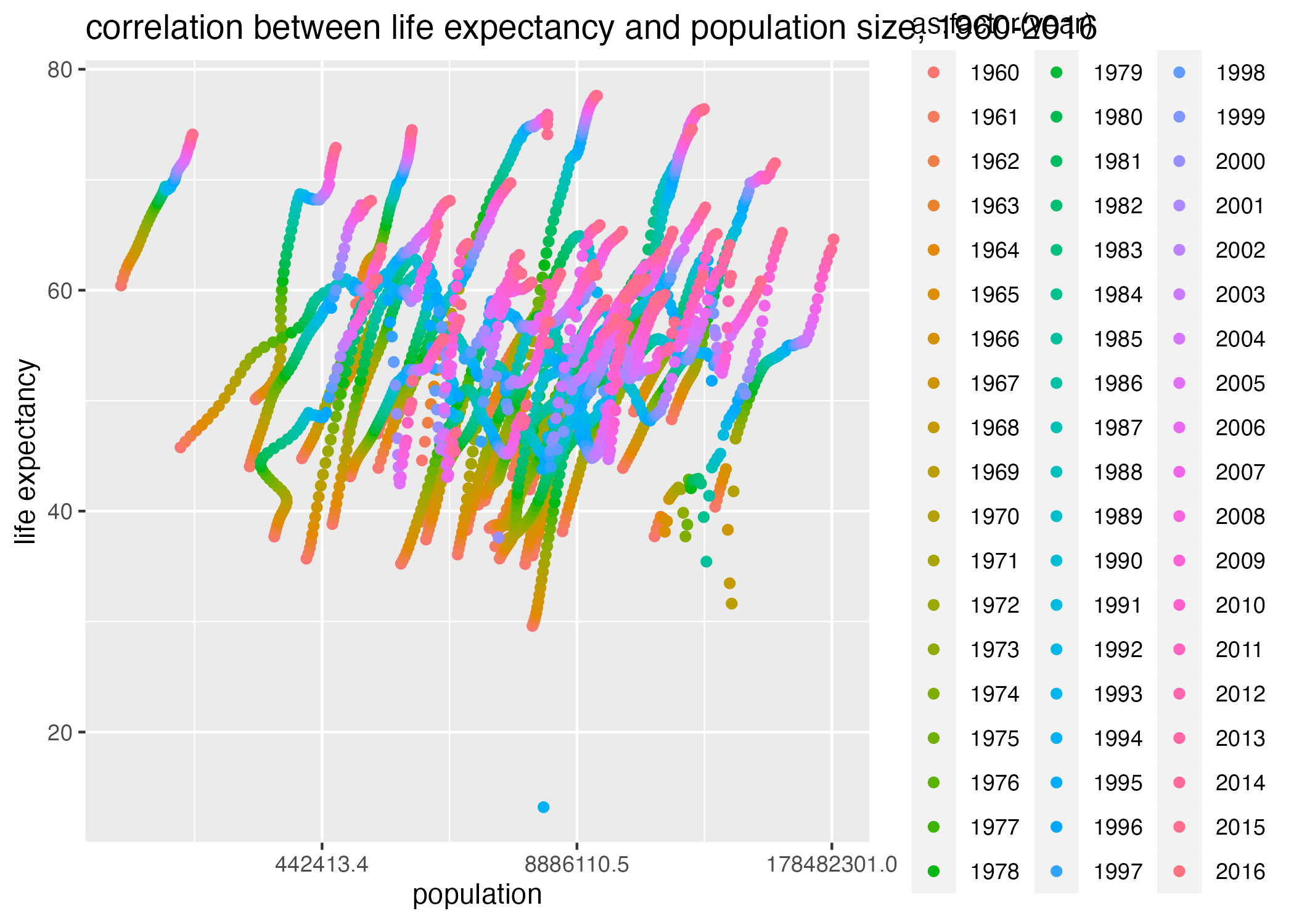
The code chunk below regenerates these figures, with points colored by the year during which the observations were reported. Notice that I am now using the africadata subset to generate these figures, as this dataset also contains the year variable.
## life_expectancy vs infant_mortality stratified by yearplot3 =ggplot() +geom_point(data = africadata, aes(x = infant_mortality, y = life_expectancy, col =as.factor(year))) +labs(x ="infant mortality", y ="life expectancy", title ="correlation between life expectancy and infant mortality in Africa, 1960 - 2016")plot4 =ggplot() +geom_point(data = africadata, aes(x = population, y = life_expectancy, col =as.factor(year))) +scale_x_continuous(trans ="log") +labs(x ="population", y ="life expectancy", title ="correlation between life expectancy and population size, 1960-2016")figure_file =here("coding-exercise","results", "figures","life_exp_inf_mort_byyears.png")ggsave(filename = figure_file, plot=plot3)
Figure 3: life expectancy by infant mortality, Africa, by year.
Figure 4: life expectancy by population size, Africa, by year.
Here, we see that “lines” in our data demonstrate how population size and infant mortality each correlate with year. However, this is visually difficult to disentangle. What we can see, particularly from our second plot, is that life expectancy appears somewhat constant across a range of population sizes within the same year.
Let’s recreate these plots, but only choose observations from a single year.
More processing
The infant_mortality variable within africandata contains many NAs. The code below determines which years contain missing (NA) data for infant mortality.
## determine which years contain missing infant mortality datamissing_IM_years =levels(factor(africadata[is.na(africadata$infant_mortality), "year"])) # which levels of factor "year" contain missing data for vairable "infant mortality"?print(paste("Infant mortality data is missing from the years", paste(missing_IM_years, collapse =" "))) #print these years
[1] "Infant mortality data is missing from the years 1960 1961 1962 1963 1964 1965 1966 1967 1968 1969 1970 1971 1972 1973 1974 1975 1976 1977 1978 1979 1980 1981 2016"
Infant mortality data is missing from observations between 1960-1981, and again from 2016. Between 1981 and 2016, then, every observation from each year contains infant mortality data. So, we will plot life_expectancy against infant_mortality from observations taken during a year within that time frame, say, the year 2000.
More plotting
The variable population is not missing data from the year 2000, so we can also plot life expectancy against population for observations taken in 2000, as well.
## extract observations from the year 2000 only and save in a new dataframeafricadata_2000 = africadata %>%filter(year ==2000)## check str(africadata_2000) #all variables from africadata included
'data.frame': 51 obs. of 9 variables:
$ country : Factor w/ 185 levels "Albania","Algeria",..: 2 3 18 22 26 27 29 31 32 33 ...
$ year : int 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...
$ infant_mortality: num 33.9 128.3 89.3 52.4 96.2 ...
$ life_expectancy : num 73.3 52.3 57.2 47.6 52.6 46.7 54.3 68.4 45.3 51.5 ...
$ fertility : num 2.51 6.84 5.98 3.41 6.59 7.06 5.62 3.7 5.45 7.35 ...
$ population : num 31183658 15058638 6949366 1736579 11607944 ...
$ gdp : num 5.48e+10 9.13e+09 2.25e+09 5.63e+09 2.61e+09 ...
$ continent : Factor w/ 5 levels "Africa","Americas",..: 1 1 1 1 1 1 1 1 1 1 ...
$ region : Factor w/ 22 levels "Australia and New Zealand",..: 11 10 20 17 20 5 10 20 10 10 ...
summary(africadata_2000) #and each variable is of the same class as corresponding africadata variables
country year infant_mortality life_expectancy
Algeria : 1 Min. :2000 Min. : 12.30 Min. :37.60
Angola : 1 1st Qu.:2000 1st Qu.: 60.80 1st Qu.:51.75
Benin : 1 Median :2000 Median : 80.30 Median :54.30
Botswana : 1 Mean :2000 Mean : 78.93 Mean :56.36
Burkina Faso: 1 3rd Qu.:2000 3rd Qu.:103.30 3rd Qu.:60.00
Burundi : 1 Max. :2000 Max. :143.30 Max. :75.00
(Other) :45
fertility population gdp continent
Min. :1.990 Min. : 81154 Min. :2.019e+08 Africa :51
1st Qu.:4.150 1st Qu.: 2304687 1st Qu.:1.274e+09 Americas: 0
Median :5.550 Median : 8799165 Median :3.238e+09 Asia : 0
Mean :5.156 Mean : 15659800 Mean :1.155e+10 Europe : 0
3rd Qu.:5.960 3rd Qu.: 17391242 3rd Qu.:8.654e+09 Oceania : 0
Max. :7.730 Max. :122876723 Max. :1.329e+11
region
Eastern Africa :16
Western Africa :16
Middle Africa : 8
Northern Africa : 6
Southern Africa : 5
Australia and New Zealand: 0
(Other) : 0
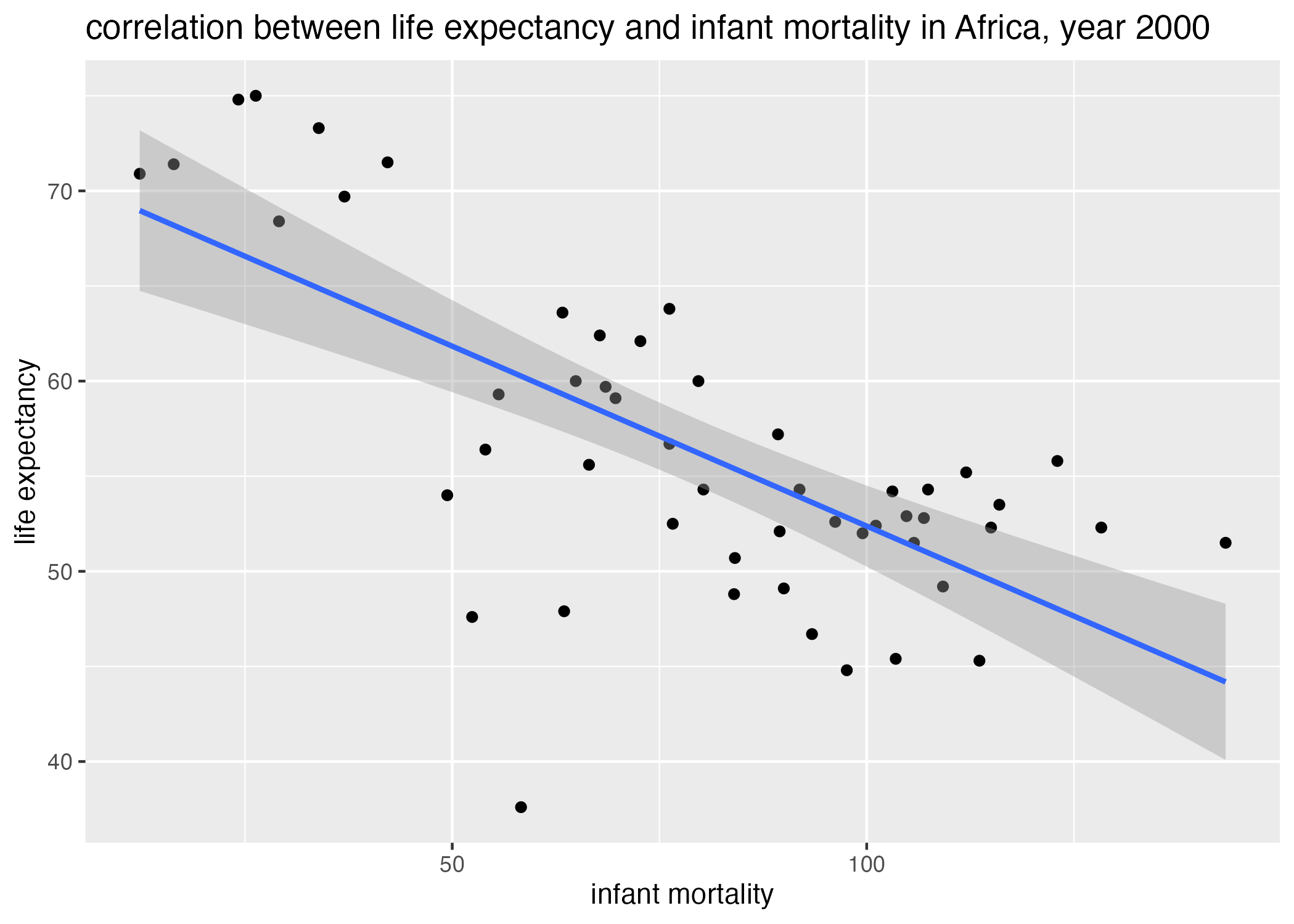
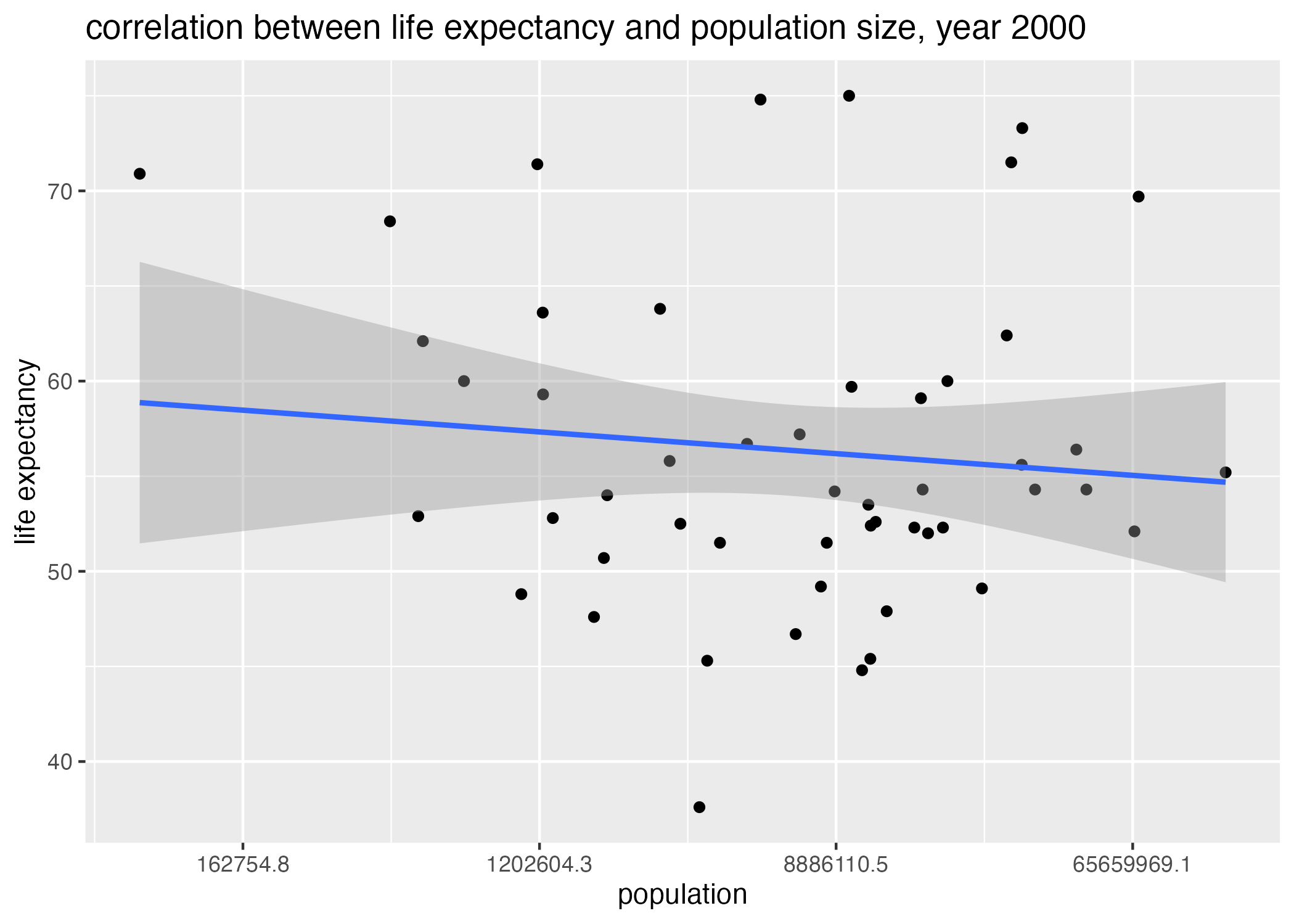
## plot## life_expectancy vs infant_mortality in the year 2000plot5 =ggplot() +geom_point(data = africadata_2000, aes(x = infant_mortality, y = life_expectancy)) +geom_smooth(data = africadata_2000, aes(x = infant_mortality, y = life_expectancy), method ='lm') +labs(x ="infant mortality", y ="life expectancy", title ="correlation between life expectancy and infant mortality in Africa, year 2000")plot6 =ggplot() +geom_point(data = africadata_2000, aes(x = population, y = life_expectancy)) +scale_x_continuous(trans ="log") +geom_smooth(data = africadata_2000, aes(x = population, y = life_expectancy), method ='lm') +labs(x ="population", y ="life expectancy", title ="correlation between life expectancy and population size, year 2000")figure_file =here("coding-exercise","results", "figures","life_exp_inf_mort_2000.png")ggsave(filename = figure_file, plot=plot5)
Saving 7 x 5 in image
`geom_smooth()` using formula = 'y ~ x'
Saving 7 x 5 in image
`geom_smooth()` using formula = 'y ~ x'
Figure 5: life expectancy by infant mortality, Africa 2000.
Figure 6: life expectancy by population size, Africa 2000.
Are these correlations (linear regressions) significant?
Simple model fits
The following code chunk utilizes the lm() function in R to determine the best-fit, simple linear regression model with life_expectancy in the year 2000 as the outcome variable and either infant_mortality or population as the predictor.
# linear regression, fixed effect, life expectancy ~ infant_mortalityfit1 =lm(data = africadata_2000, life_expectancy ~ infant_mortality) #results saved in lm object `fit1`# linear regression, fixed effect, life expectancy ~ infant_mortalityfit2 =lm(data = africadata_2000, life_expectancy ~ population) #results saved in lm object `fit2`# print summary of lm objects fit1 and fit2summary(fit1)
Call:
lm(formula = life_expectancy ~ infant_mortality, data = africadata_2000)
Residuals:
Min 1Q Median 3Q Max
-22.6651 -3.7087 0.9914 4.0408 8.6817
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 71.29331 2.42611 29.386 < 2e-16 ***
infant_mortality -0.18916 0.02869 -6.594 2.83e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.221 on 49 degrees of freedom
Multiple R-squared: 0.4701, Adjusted R-squared: 0.4593
F-statistic: 43.48 on 1 and 49 DF, p-value: 2.826e-08
summary(fit2)
Call:
lm(formula = life_expectancy ~ population, data = africadata_2000)
Residuals:
Min 1Q Median 3Q Max
-18.429 -4.602 -2.568 3.800 18.802
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.593e+01 1.468e+00 38.097 <2e-16 ***
population 2.756e-08 5.459e-08 0.505 0.616
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.524 on 49 degrees of freedom
Multiple R-squared: 0.005176, Adjusted R-squared: -0.01513
F-statistic: 0.2549 on 1 and 49 DF, p-value: 0.6159
table1 = fit1 %>%tbl_regression() #save summaries as tables using tbl_regression() function from flextable packagetable2 = fit2 %>%tbl_regression() #save summaries as tables using tbl_regression() function from flextable package# save summary tablessummarytable_file =here("coding-exercise","results", "tables-files", "lm_life_exp_inf_mort.rds")saveRDS(table1, file = summarytable_file)summarytable_file =here("coding-exercise","results", "tables-files", "lm_life_exp_pop.rds")saveRDS(table2, file = summarytable_file)# extract p-values from summaries to display on figuresp.infant_mortality =unname(summary(fit1)$coefficients[,"Pr(>|t|)"])[2]p.population =unname(summary(fit2)$coefficients[,"Pr(>|t|)"])[2]
Table 1: Linear regression model of life expectancy by infant mortality.
Characteristic
Beta
95% CI
p-value
infant_mortality
-0.19
-0.25, -0.13
<0.001
Table 2: Linear regression model of life expectancy by population size.
Characteristic
Beta
95% CI
p-value
population
0.00
0.00, 0.00
0.6
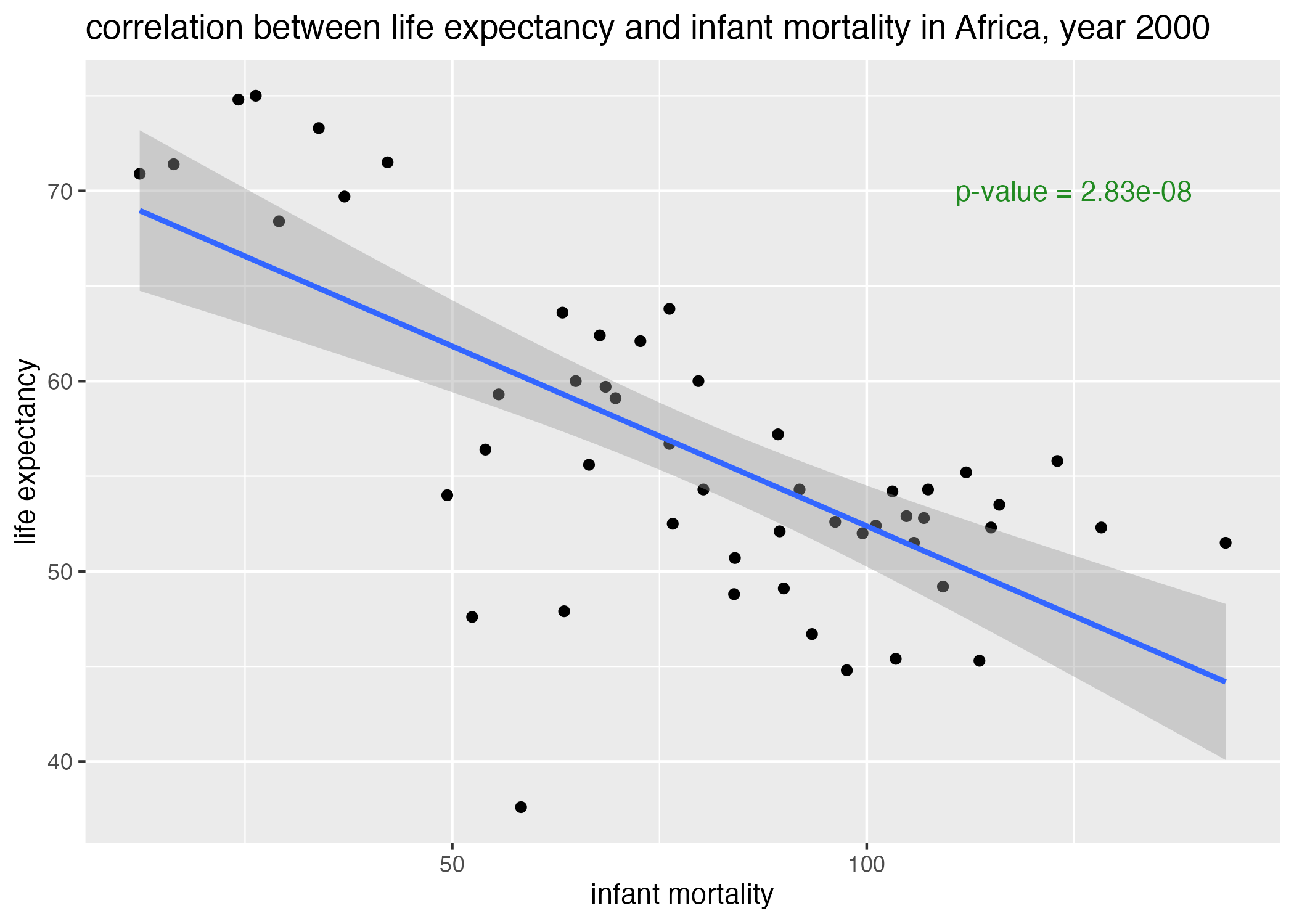
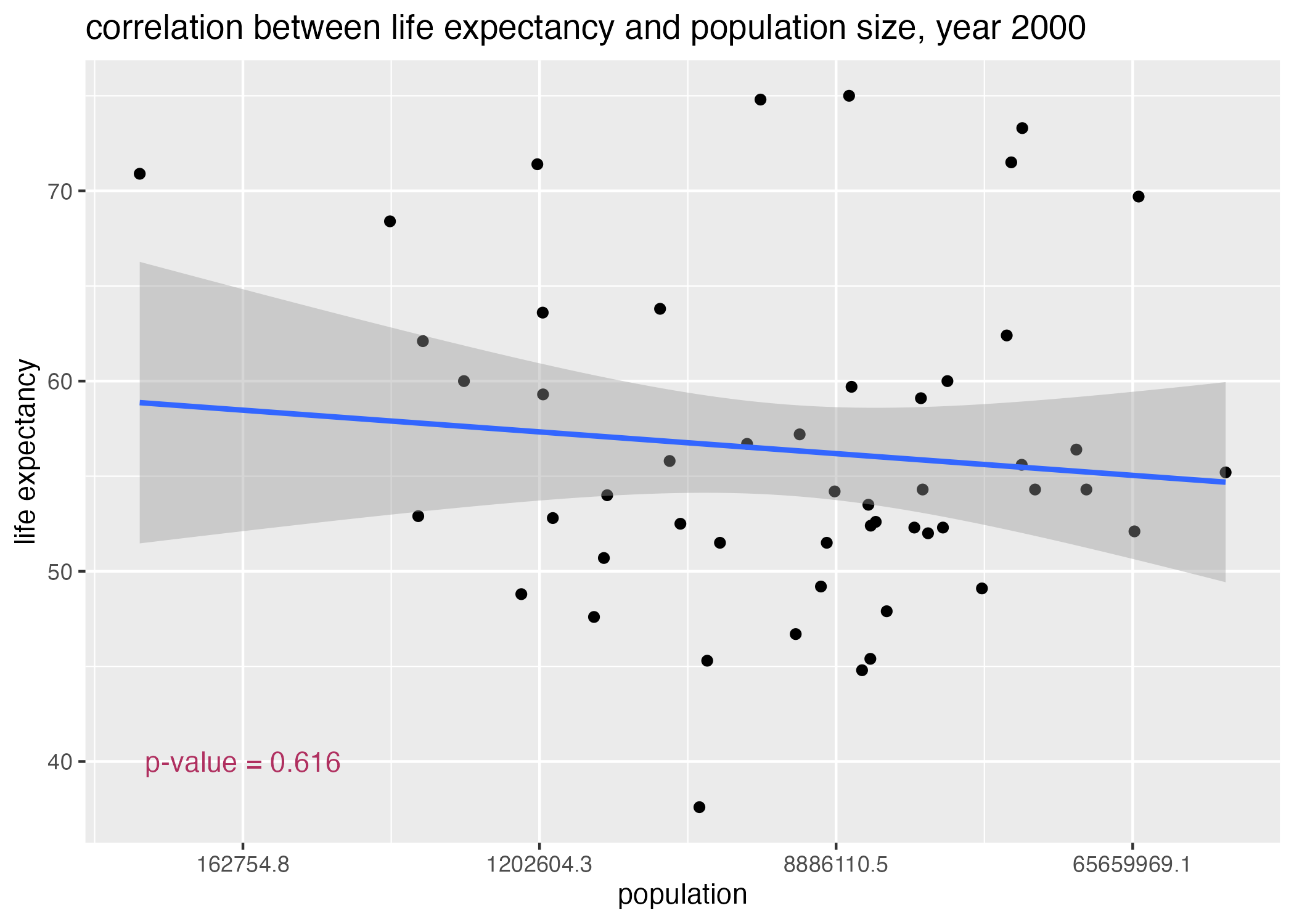
## replot with pvals ## life_expectancy vs infant_mortality in the year 2000plot7 =ggplot() +geom_point(data = africadata_2000, aes(x = infant_mortality, y = life_expectancy)) +geom_smooth(data = africadata_2000, aes(x = infant_mortality, y = life_expectancy), method ='lm') +annotate(geom ="text", x =125, y =70, label =paste("p-value =", signif(p.infant_mortality, digits =3)), color ="forestgreen") +labs(x ="infant mortality", y ="life expectancy", title ="correlation between life expectancy and infant mortality in Africa, year 2000")plot8 =ggplot() +geom_point(data = africadata_2000, aes(x = population, y = life_expectancy)) +scale_x_continuous(trans ="log") +geom_smooth(data = africadata_2000, aes(x = population, y = life_expectancy), method ='lm') +annotate(geom ="text", x =163000, y =40, label =paste("p-value =", signif(p.population, digits =3)), color ="maroon") +labs(x ="population", y ="life expectancy", title ="correlation between life expectancy and population size, year 2000")figure_file =here("coding-exercise","results", "figures","life_exp_inf_mort_reg.png")ggsave(filename = figure_file, plot=plot7)
Saving 7 x 5 in image
`geom_smooth()` using formula = 'y ~ x'
Saving 7 x 5 in image
`geom_smooth()` using formula = 'y ~ x'
Figure 7: linear regression of life expectancy by infant mortality, Africa 2000.
Figure 8: linear regression of life expectancy by population size, Africa 2000.
Life expectancy appears to decrease with infant mortality, while decreasing only slightly with population size (Figure 7, Figure 8). Using a definition of \(pvalue < 0.05\) as significance, it is evident that population size is a poor predictor of life expectancy (\(p = 0.6 > 0.05\)). However, infant mortality is in fact a better, significant predictor of life expectancy (\(p = 2 \times 10^{-8}\)) (Table 1, Table 2). Thus, we fail to reject the null hypothesis that life expectancy is not correlated with population size, but do reject the null hypothesis that life expectancy is not correlated with infant mortality rates.
This section is contributed by Taylor Glass.
Exploring the dataset
I chose to explore the ‘movie’ dataset in the dslabs package. I used the help() function to find the description of the dataset and an explanation of the 7 variables it includes. I used the str() function to determine there are 100,004 observations of 7 variables. There are 4 integer variables, 1 character variable, 1 numeric variable and one factor variable with 901 levels. I used the summary() function to examine the range of each numerical variable. The year the movie was released ranges from 1902 to 2016. There are 6 distinct genres along with an ‘other’ option. The mean rating for all 100,004 movies included in the dataset is 3.544.
help("movielens") ##learn about the datasetstr(movielens) ##determine dimensions of dataset
summary(movielens) ##explore ranges for numerical variables
movieId title year
Min. : 1 Length:100004 Min. :1902
1st Qu.: 1028 Class :character 1st Qu.:1987
Median : 2406 Mode :character Median :1995
Mean : 12549 Mean :1992
3rd Qu.: 5418 3rd Qu.:2001
Max. :163949 Max. :2016
NA's :7
genres userId rating timestamp
Drama : 7757 Min. : 1 Min. :0.500 Min. :7.897e+08
Comedy : 6748 1st Qu.:182 1st Qu.:3.000 1st Qu.:9.658e+08
Comedy|Romance : 3973 Median :367 Median :4.000 Median :1.110e+09
Drama|Romance : 3462 Mean :347 Mean :3.544 Mean :1.130e+09
Comedy|Drama : 3272 3rd Qu.:520 3rd Qu.:4.000 3rd Qu.:1.296e+09
Comedy|Drama|Romance: 3204 Max. :671 Max. :5.000 Max. :1.477e+09
(Other) :71588
Processing/cleaning data
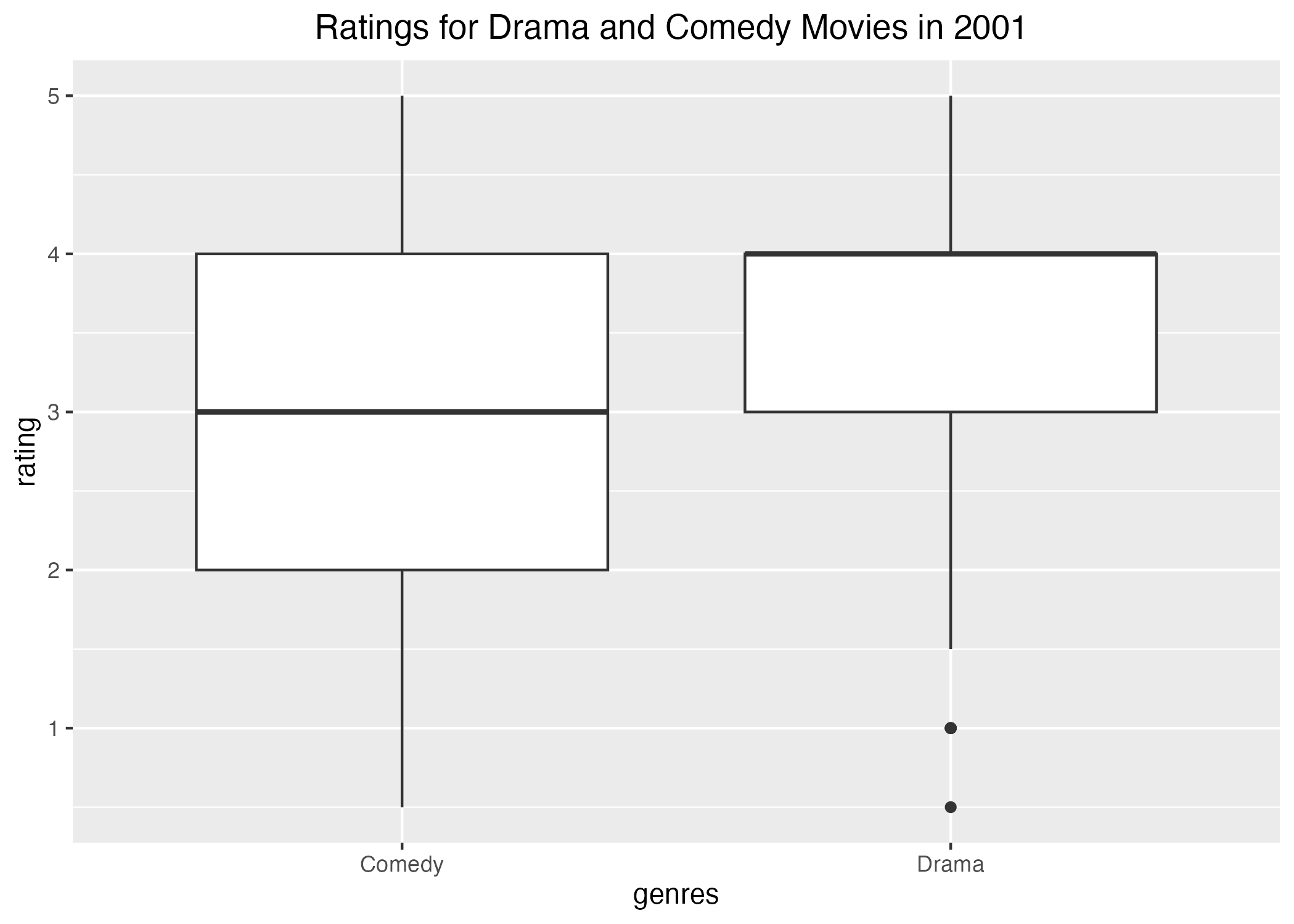
I decided to create a subset of this data with movie ratings from just the year that I was born, 2001. I used the filter function to create a new object called ‘mymovies’ with 3442 observations of 7 variables. I decided to explore the ratings among different genres of movies during 2001. I created a boxplot using genres as the categorical variable, which was very messy and not helpful. I decided to filter the datset further by only including movies in the drama and comedy genres, which limited the dataset to 319 observations of 7 variables. I selected the title, genres, and rating columns because they are the only variables useful for this analysis. When I created the second boxplot with the final dataset called ‘mymovies3’, it became easy to view the spread in ratings for drama and comedy movies released in 2001. The average rating for comedy movies is a 3, while the average rating for drama movies is a 4.
mymovies <- movielens %>%filter(year ==2001) ##limit dataset to movies released in 2001str(mymovies)
mymovies %>%ggplot(aes(x=genres, y=rating)) +##use genres as the categorical variable and rating as the numerical variablegeom_boxplot() ##create exploratory boxplot
mymovies2 <- mymovies %>%filter(year ==2001& genres %in%c("Drama", "Comedy")) ##further filter dataset to include 2 genresstr(mymovies2)
mymovies3 <- mymovies2 %>%select("title", "genres", "rating") ##select 3 columns of useful information str(mymovies3)
'data.frame': 319 obs. of 3 variables:
$ title : chr "American Pie 2" "American Pie 2" "Dish, The" "Closet, The (Placard, Le)" ...
$ genres: Factor w/ 901 levels "(no genres listed)",..: 596 596 596 596 596 596 762 596 596 762 ...
$ rating: num 3.5 3.5 1 2 3 4 3.5 4 3 3 ...
Create a few exploratory figures
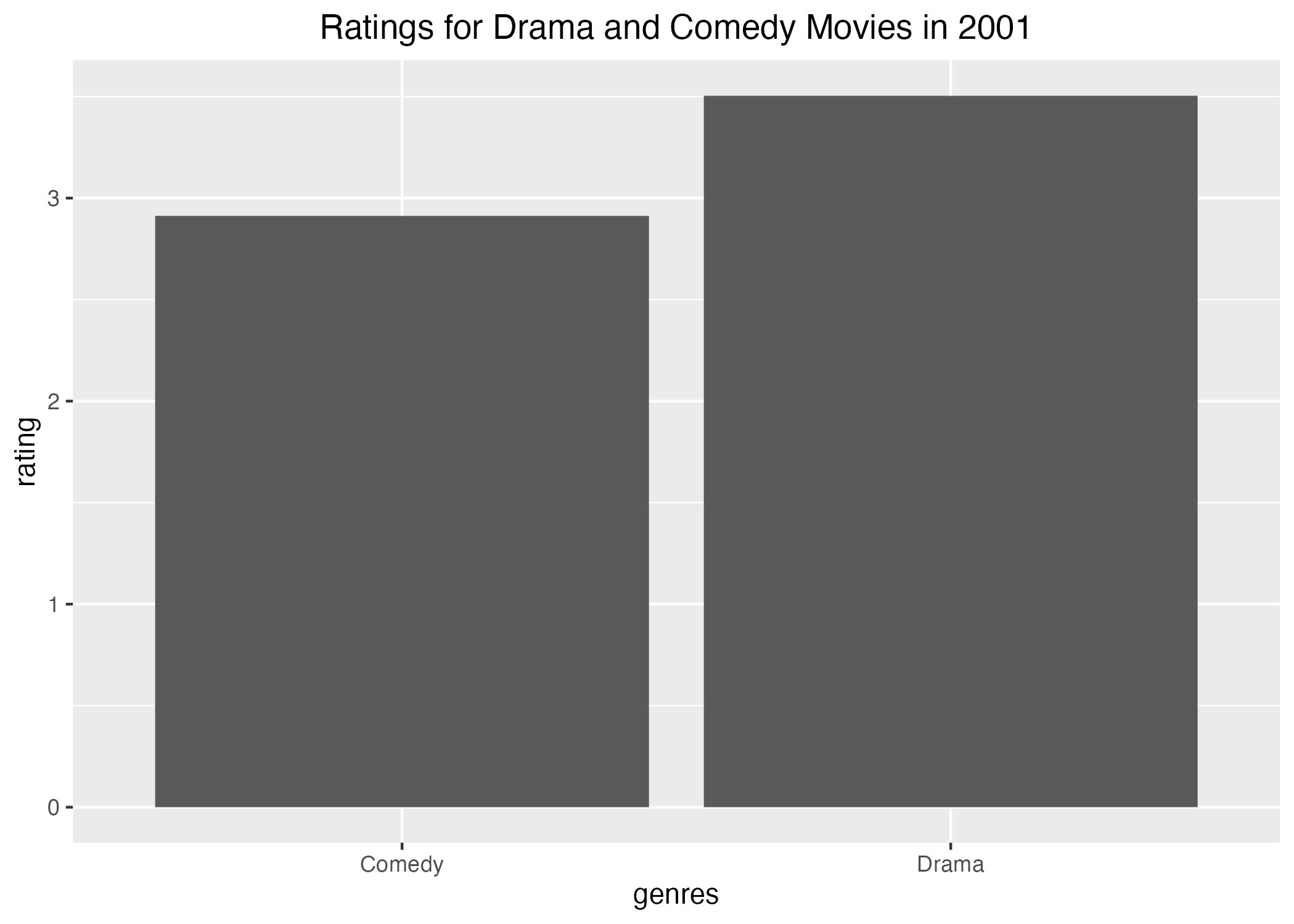
I created the second boxplot with the final dataset called ‘mymovies3’, and it became easy to view the spread in ratings for drama and comedy movies released in 2001. I added a title for the boxplot and centered it to make it easier to read. The average rating for comedy movies is a 3, while the average rating for drama movies is a 4. I practiced saving this image to the folder previously created by Cora using the here() and ggsave() functions. To create another visualization of this data, I used the mean ratings from each category in a bar graph. The means of the ratings for each genre are displayed with better precision in this visualization. The mean rating for comedy movies is a little less than 3 at about 2.9 while the average rating for drama movies seems lower at about 3.5. This discrepancy could be explained by the 2 outliers shown in the drama category on the boxplot because these observations are skewing the mean. I saved this graph to the same folder with the boxplot using the here() and ggsave() functions. I also created a table of my final dataset to include the movie titles of both genres with each of their ratings from reviewers. It is a little busy since there are multiple reviews for the some of the same movies, so I organized it by title to allow for quick review of all the ratings provided for each movie. The first table has been commented out, so it will not print on this rendered website. It is included to show the process of creating the better table.
boxplot <- mymovies3 %>%ggplot(aes(x=genres, y=rating)) +##visualize the ratings for each genre of movie geom_boxplot() +##create clean boxplot to compare ratings across genres in 2001labs(title ="Ratings for Drama and Comedy Movies in 2001 ") +##add a title to the graphtheme(plot.title =element_text(hjust =0.5)) ##center the title figure_file <-here("coding-exercise", "results", "figures", "movies_boxplot.png") ##inform R on where to save the imageggsave(filename = figure_file, plot = boxplot) ##save the image in the predefined location
Saving 7 x 5 in image
## ensure the figure renders on the website#| label: fig-inf-mort-all. ##create a label for the final figure#| fig-cap: "life expectancy by infant mortality, Africa, 1960-2016." ##create a label for the final figure#| echo: FALSE ##ensure these lines are not reproduced in the rendered versionknitr::include_graphics(here("coding-exercise","results","figures","movies_boxplot.png")) ##tag the saved location
bargraph <- mymovies3 %>%ggplot(aes(x=genres, y=rating)) +##visualize the ratings for each genre of moviegeom_bar(stat ="summary", fun ="mean") +##use the mean of each rating for the barslabs(title ="Ratings for Drama and Comedy Movies in 2001") +##create a title for the graphtheme(plot.title =element_text(hjust =0.5)) ##center the titlefigure_file2 <-here("coding-exercise", "results", "figures", "movies_bargraph.png") ##inform R on where to save the imageggsave(filename = figure_file2, plot = bargraph) ##save the image in the predefined location
Saving 7 x 5 in image
## ensure the figure renders on the website#| label: fig-inf-mort-all ##create a label for the final figure#| fig-cap: "life expectancy by infant mortality, Africa, 1960-2016." ##create a label for the final figure#| echo: FALSE ##ensure these lines are not reproduced in the rendered versionknitr::include_graphics(here("coding-exercise","results","figures","movies_bargraph.png")) ##tag the saved location
## knitr::kable(mymovies3) ##create a table to display movie titles with their ratings## comment out the first table so it will not show on the rendered websitebetter_table <-arrange(mymovies3, title) ##organize the table by title knitr::kable(better_table) ##view new table with all ratings for each movie grouped together by title
title
genres
rating
61*
Drama
3.0
61*
Drama
4.0
Ali
Drama
3.5
Ali
Drama
3.0
Ali
Drama
3.0
Ali
Drama
4.0
Ali
Drama
2.5
Ali
Drama
2.5
All Over the Guy
Comedy
4.0
All Over the Guy
Comedy
4.0
All Over the Guy
Comedy
5.0
American Pie 2
Comedy
3.5
American Pie 2
Comedy
3.5
American Pie 2
Comedy
4.0
American Pie 2
Comedy
4.5
American Pie 2
Comedy
4.0
American Pie 2
Comedy
3.0
American Pie 2
Comedy
4.5
American Pie 2
Comedy
4.0
American Pie 2
Comedy
4.0
American Pie 2
Comedy
1.5
American Pie 2
Comedy
4.0
American Pie 2
Comedy
2.5
American Pie 2
Comedy
2.5
American Pie 2
Comedy
2.5
American Pie 2
Comedy
2.0
American Pie 2
Comedy
2.5
American Pie 2
Comedy
3.0
American Pie 2
Comedy
2.0
American Pie 2
Comedy
3.0
American Pie 2
Comedy
3.5
American Pie 2
Comedy
3.0
American Pie 2
Comedy
3.0
American Pie 2
Comedy
0.5
American Pie 2
Comedy
3.0
American Pie 2
Comedy
1.0
American Pie 2
Comedy
1.5
American Pie 2
Comedy
3.5
American Pie 2
Comedy
2.0
American Pie 2
Comedy
1.0
American Pie 2
Comedy
3.5
American Pie 2
Comedy
4.0
American Pie 2
Comedy
2.5
American Pie 2
Comedy
3.0
American Pie 2
Comedy
2.5
American Pie 2
Comedy
3.5
American Pie 2
Comedy
3.0
American Pie 2
Comedy
0.5
American Pie 2
Comedy
3.0
American Pie 2
Comedy
4.0
American Rhapsody, An
Drama
2.0
American Rhapsody, An
Drama
3.5
Animal, The
Comedy
4.0
Animal, The
Comedy
2.0
Animal, The
Comedy
3.0
Animal, The
Comedy
2.5
Animal, The
Comedy
2.0
Animal, The
Comedy
1.5
Animal, The
Comedy
3.0
Animal, The
Comedy
2.0
Anniversary Party, The
Drama
4.0
Anniversary Party, The
Drama
2.0
Anniversary Party, The
Drama
3.0
Anniversary Party, The
Drama
2.0
Anniversary Party, The
Drama
4.5
Anniversary Party, The
Drama
4.0
Bad Guy (Nabbeun namja)
Drama
2.5
Believer, The
Drama
4.0
Believer, The
Drama
4.5
Believer, The
Drama
4.5
Believer, The
Drama
4.0
Blow Dry (a.k.a. Never Better)
Comedy
4.5
Bubble Boy
Comedy
2.5
Bubble Boy
Comedy
4.0
Bubble Boy
Comedy
1.5
Chelsea Walls
Drama
2.0
Chelsea Walls
Drama
4.0
Closet, The (Placard, Le)
Comedy
2.0
Closet, The (Placard, Le)
Comedy
4.0
Curse of the Jade Scorpion, The
Comedy
4.0
Curse of the Jade Scorpion, The
Comedy
4.0
Deep End, The
Drama
3.5
Deep End, The
Drama
4.0
Deep End, The
Drama
4.0
Deep End, The
Drama
4.0
Deep End, The
Drama
4.0
Diamond Men
Drama
3.5
Dish, The
Comedy
1.0
Dish, The
Comedy
4.0
Dish, The
Comedy
4.0
Dish, The
Comedy
4.0
Dish, The
Comedy
4.5
Dish, The
Comedy
4.5
Dish, The
Comedy
4.0
Dish, The
Comedy
2.0
Dish, The
Comedy
3.0
Dish, The
Comedy
4.0
Dish, The
Comedy
4.0
Dr. Dolittle 2
Comedy
0.5
Dr. Dolittle 2
Comedy
0.5
Dr. Dolittle 2
Comedy
3.0
Dr. Dolittle 2
Comedy
4.0
Emperor’s New Clothes, The
Comedy
4.5
Freddy Got Fingered
Comedy
0.5
Freddy Got Fingered
Comedy
1.5
Freddy Got Fingered
Comedy
3.0
Freddy Got Fingered
Comedy
2.0
Freddy Got Fingered
Comedy
1.0
Freddy Got Fingered
Comedy
3.5
Freddy Got Fingered
Comedy
0.5
Friends and Family
Comedy
5.0
Grey Zone, The
Drama
3.5
Grey Zone, The
Drama
4.0
Hardball
Drama
4.0
Hearts in Atlantis
Drama
4.0
Hearts in Atlantis
Drama
3.0
How High
Comedy
3.0
How High
Comedy
2.0
How I Killed My Father (a.k.a. My Father and I) (Comment j’ai tué mon Père)
Drama
1.0
Hush!
Drama
4.0
I Am Sam
Drama
1.0
I Am Sam
Drama
4.5
I Am Sam
Drama
4.0
I Am Sam
Drama
3.5
I Am Sam
Drama
3.5
I Am Sam
Drama
3.0
I Am Sam
Drama
4.5
I Am Sam
Drama
3.5
I Am Sam
Drama
4.5
I Am Sam
Drama
2.5
I Am Sam
Drama
2.5
I Am Sam
Drama
3.5
I Am Sam
Drama
3.0
I Am Sam
Drama
4.5
In the Bedroom
Drama
5.0
In the Bedroom
Drama
3.0
In the Bedroom
Drama
4.0
In the Bedroom
Drama
4.0
In the Bedroom
Drama
3.0
In the Bedroom
Drama
5.0
In the Bedroom
Drama
4.0
In the Bedroom
Drama
5.0
In the Bedroom
Drama
4.0
In the Bedroom
Drama
4.0
Invincible
Drama
1.5
Iris
Drama
3.0
Iris
Drama
3.0
Josie and the Pussycats
Comedy
1.0
Josie and the Pussycats
Comedy
4.0
Kandahar (Safar e Ghandehar)
Drama
3.0
Kandahar (Safar e Ghandehar)
Drama
4.0
Kandahar (Safar e Ghandehar)
Drama
3.0
L.I.E.
Drama
3.0
L.I.E.
Drama
4.0
L.I.E.
Drama
5.0
L.I.E.
Drama
2.0
Lammbock
Comedy
3.5
Life as a House
Drama
4.5
Life as a House
Drama
2.0
Life as a House
Drama
5.0
Life as a House
Drama
4.0
Life as a House
Drama
4.0
Life as a House
Drama
3.5
Life as a House
Drama
3.5
Life as a House
Drama
4.0
Lost and Delirious
Drama
4.0
Lost and Delirious
Drama
3.0
Made
Comedy
2.0
Made
Comedy
2.0
Made
Comedy
3.0
Made
Comedy
2.0
Made
Comedy
4.0
Manic
Drama
2.0
Not Another Teen Movie
Comedy
2.0
Not Another Teen Movie
Comedy
3.0
Not Another Teen Movie
Comedy
3.0
Not Another Teen Movie
Comedy
5.0
Not Another Teen Movie
Comedy
3.5
Not Another Teen Movie
Comedy
3.0
Not Another Teen Movie
Comedy
2.5
Not Another Teen Movie
Comedy
4.0
Not Another Teen Movie
Comedy
3.0
Not Another Teen Movie
Comedy
2.5
Not Another Teen Movie
Comedy
1.0
Not Another Teen Movie
Comedy
2.5
Not Another Teen Movie
Comedy
3.0
Nowhere in Africa (Nirgendwo in Afrika)
Drama
4.5
Nowhere in Africa (Nirgendwo in Afrika)
Drama
4.5
Nowhere in Africa (Nirgendwo in Afrika)
Drama
1.0
Nowhere in Africa (Nirgendwo in Afrika)
Drama
4.0
Nowhere in Africa (Nirgendwo in Afrika)
Drama
4.5
O
Drama
3.0
O
Drama
1.0
O
Drama
0.5
On the Edge
Drama
5.0
One Night at McCool’s
Comedy
4.0
One Night at McCool’s
Comedy
3.0
One Night at McCool’s
Comedy
3.0
Piano Teacher, The (La pianiste)
Drama
4.5
Piano Teacher, The (La pianiste)
Drama
1.0
Piano Teacher, The (La pianiste)
Drama
4.5
Piano Teacher, The (La pianiste)
Drama
4.0
Piano Teacher, The (La pianiste)
Drama
3.0
Piano Teacher, The (La pianiste)
Drama
5.0
Piano Teacher, The (La pianiste)
Drama
5.0
Piñero
Drama
1.5
Piñero
Drama
4.0
Rat Race
Comedy
4.0
Rat Race
Comedy
3.0
Rat Race
Comedy
3.0
Rat Race
Comedy
1.5
Rat Race
Comedy
5.0
Rat Race
Comedy
1.5
Rat Race
Comedy
3.0
Rat Race
Comedy
2.5
Scary Movie 2
Comedy
3.0
Scary Movie 2
Comedy
2.0
Scary Movie 2
Comedy
2.0
Scary Movie 2
Comedy
5.0
Scary Movie 2
Comedy
4.0
Scary Movie 2
Comedy
1.0
Scary Movie 2
Comedy
1.5
Scary Movie 2
Comedy
2.0
Scary Movie 2
Comedy
2.0
Scary Movie 2
Comedy
3.0
Scary Movie 2
Comedy
2.0
Scary Movie 2
Comedy
3.5
Scary Movie 2
Comedy
2.0
Scary Movie 2
Comedy
1.0
Scary Movie 2
Comedy
2.5
Scary Movie 2
Comedy
2.5
Scary Movie 2
Comedy
0.5
Scary Movie 2
Comedy
2.0
Scary Movie 2
Comedy
2.0
See Spot Run
Comedy
1.0
Shipping News, The
Drama
1.0
Shipping News, The
Drama
3.0
Shipping News, The
Drama
3.0
Shipping News, The
Drama
2.0
Son’s Room, The (Stanza del figlio, La)
Drama
3.0
Son’s Room, The (Stanza del figlio, La)
Drama
4.0
Sugar & Spice
Comedy
3.5
Sugar & Spice
Comedy
3.0
Taking Sides
Drama
2.0
Tape
Drama
3.0
Tape
Drama
4.0
Tape
Drama
3.0
Tape
Drama
4.5
The Last Brickmaker in America
Drama
5.0
Things Behind the Sun
Drama
4.0
Thirteen Conversations About One Thing (a.k.a. 13 Conversations)
Drama
2.5
Thirteen Conversations About One Thing (a.k.a. 13 Conversations)
Drama
4.0
Thirteen Conversations About One Thing (a.k.a. 13 Conversations)
Drama
4.5
Thirteen Conversations About One Thing (a.k.a. 13 Conversations)
Drama
5.0
Thirteen Conversations About One Thing (a.k.a. 13 Conversations)
Drama
4.5
Thirteen Conversations About One Thing (a.k.a. 13 Conversations)
Drama
3.5
To the Left of the Father (Lavoura Arcaica)
Drama
5.0
Tomcats
Comedy
2.5
Town & Country
Comedy
2.0
Wash, The
Comedy
2.5
Waterboys
Comedy
4.0
Wet Hot American Summer
Comedy
4.0
Wet Hot American Summer
Comedy
4.0
Wet Hot American Summer
Comedy
2.5
Wet Hot American Summer
Comedy
2.0
Wet Hot American Summer
Comedy
3.0
Wet Hot American Summer
Comedy
1.0
What Time Is It There? (Ni neibian jidian)
Drama
5.0
What Time Is It There? (Ni neibian jidian)
Drama
4.0
White Sound, The (Das weiße Rauschen)
Drama
5.0
Wit
Drama
3.0
Wit
Drama
4.0
Wit
Drama
3.5
Zoolander
Comedy
3.0
Zoolander
Comedy
3.0
Zoolander
Comedy
2.0
Zoolander
Comedy
2.0
Zoolander
Comedy
4.0
Zoolander
Comedy
0.5
Zoolander
Comedy
4.0
Zoolander
Comedy
4.0
Zoolander
Comedy
4.0
Zoolander
Comedy
4.5
Zoolander
Comedy
0.5
Zoolander
Comedy
2.0
Zoolander
Comedy
2.5
Zoolander
Comedy
4.0
Zoolander
Comedy
4.0
Zoolander
Comedy
3.5
Zoolander
Comedy
4.0
Zoolander
Comedy
3.5
Zoolander
Comedy
3.0
Zoolander
Comedy
2.0
Zoolander
Comedy
1.0
Zoolander
Comedy
5.0
Zoolander
Comedy
3.0
Zoolander
Comedy
3.5
Zoolander
Comedy
3.0
Zoolander
Comedy
2.5
Zoolander
Comedy
4.0
Zoolander
Comedy
2.0
Zoolander
Comedy
2.0
Zoolander
Comedy
5.0
Zoolander
Comedy
4.0
Zoolander
Comedy
3.0
Zoolander
Comedy
4.5
Zoolander
Comedy
5.0
Zoolander
Comedy
4.0
Zoolander
Comedy
3.5
Zoolander
Comedy
4.5
Zoolander
Comedy
2.0
Zoolander
Comedy
4.0
Zoolander
Comedy
3.5
Zoolander
Comedy
4.5
Zoolander
Comedy
3.0
Zoolander
Comedy
1.5
Zoolander
Comedy
3.5
Zoolander
Comedy
3.0
Zoolander
Comedy
4.0
Simple statistical model
I decided to conduct a simple t test to determine if the mean ratings among movies in each genre are statistically different from one another. I created an object called ‘drama’ to pull the ratings for movies in the drama genre from the dataframe. I did the same thing for movies in the comedy genre and saved that object as ‘comedy’. I used the base R t.test() function to compare the average ratings between the two groups and printed the results.
drama <- mymovies3$rating[mymovies3$genres =="Drama"] ##create an object with ratings only for movies in drama genrecomedy <- mymovies3$rating[mymovies3$genres =="Comedy"] ##create an object with ratings only for movies in comedy genret.test1 <-t.test(drama, comedy) ##run a two-sample t-test between the two numeric vectorsprint(t.test1) ##show the results of the t-test
Welch Two Sample t-test
data: drama and comedy
t = 4.6912, df = 279.12, p-value = 4.257e-06
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.3433740 0.8398837
sample estimates:
mean of x mean of y
3.504000 2.912371
Results of simple statistical model
After running the two-sample t-test, I get a test statistic of 4.6912 with a tiny p-value of 4.257e-06. Since the p-value is much less than 0.05, we can reject the null hypothesis to conclude that there is a statistically significant difference between the mean ratings of drama and comedy movies in 2001. It is clear that movies in the drama genre received higher ratings from viewers compared to movies in the comedy genre in 2001.